There was a dormant problem that was found after a late refactor.
So today I've get the bxtrx work a bit forward as he shows the problem. The problem is about propagating transformations. In fact the transforms did not propagate, only the shape creation. This makes odd effects like applying Undo and then Redo to appear as shapes do translate randomly or even break. Devasted helped me with his advices on transformation work and review the changes done, so hope to behave right.
The first part of the day I've did fix a developer debug tool which exposes in a clean way all NaroCAD document tree. Hopefully will simplify some cases of visual hints do not help.
Tuesday, September 29, 2009
Bug fixing
Started bug fixing the shape intersection algorithm and also integrations with Extrude and Cut. Fixed the shape detection algorithm (the code that connects displayed shapes with Nodes), fixed an extrude bug on overlapped/intersected shapes that it wasn't extruding the correct shape.
Enabled all the functionality implemented until now and will continue fixing bugs and make all tools working properly.
Enabled all the functionality implemented until now and will continue fixing bugs and make all tools working properly.
Monday, September 28, 2009
Rendering with Sunflow
 Sunflow is an opensource raytracing engine. Right now there is an action for rendering shapes. This action give some advantakes and shows a real usage of triangularization.
Sunflow is an opensource raytracing engine. Right now there is an action for rendering shapes. This action give some advantakes and shows a real usage of triangularization.Some shapes are not drawed right, but I don't know if is NaroCAD bug, OCC triangularization bug or Sunflow bug.
I've picked rendering because there were some requests of make printing in NaroCAD, and as there is not such a large work in that, the pursposed solution was to capture the OpenGL screen and to save it to file (or to print it). It may sound handy but it will not guarantee a lot of issues, the biggest for me was that it should be just hacky to take OpenGL surface and render it to a file, it should mean at least to hack OpenCascade code.
The choices I've had so far for rendering were Sunflow, PovRay and Yafray. The Povray is huge, making to add a huge bargain to installer, Yafray is nice but I found it hard to use (from command line and to integrate it) and Sunflow was the balance between two: it was the smallest of three (it use 1M), but requires Java, which is one of the most downloaded runtimes over the internet. Also sunflow have a very easy material (named shader) setup. So the rendering goes as this: you pick the shape, you pick the shader, and you will get all at once.
I think that are still bugs, in those dialogs, but is a fully working concept. Also I've not found a proper way to pick FOV (Field of View) from OCC view. If you will find a proper way to get it, please send it via email, and I will fix it to get it right away.
Sunday, September 27, 2009
Shape intersection
Continued working at the shape intersection algorithm and succeeded to reach a quite acceptable solution: introduced in the application the concept of splitter node. A splitter collects shapes drawn into a candidates list, the ones that collide are stored into a separate list, the result of intersection is displayed (and hold into a separate list of Face shapes). If a feature like Extrude is applied on some shape generated from the intersection of other shapes, a hidden splitter node is generated with the shapes that generated that intersection, Extrude will reference this splitter node. In this way parametric propagation is possible also further modifications of the shape intersections by adding new intersecting shapes don't affect the Extrude reference. Refactored Extrude, Cut, Revolve to reference SubShapes that reference at their turn Face shapes generated from intersecting shapes. Undo/Redo seems to work well with the new added concept.
Currently the intersection algorithm is disabled on NaroCad until an Extrusion bug is fixed (Extrude sometimes picks a different intersection shape than the desire one). Also the display of the structure in the tree view needs some improvements to give access to the user to the initial shapes that generated the intersected shape. Planning to finish working at this algorithm into one more day of work and in parallel to add also wrappers for the Meshing algorithms.
Interesting that after trying at least 10-20 OpenCascade algorithms/solutions for intersecting/breaking/healing/combining wires, edges, faces, shapes, shape analysis, shape upgrade, closed area detection, closer wire extraction the only solution that worked in all cases for making a Face intersection algorithm was extremely simple: fuse all shapes and explore the resulting faces. Also Face colliding detection was made by using BRepAlgoAPI_Common algorithm and see if Face exploring iterator holds anything. The problem with these solutions is that they are not the fastest, the advantage is that they work well and cover most usage cases.
Currently the intersection algorithm is disabled on NaroCad until an Extrusion bug is fixed (Extrude sometimes picks a different intersection shape than the desire one). Also the display of the structure in the tree view needs some improvements to give access to the user to the initial shapes that generated the intersected shape. Planning to finish working at this algorithm into one more day of work and in parallel to add also wrappers for the Meshing algorithms.
Interesting that after trying at least 10-20 OpenCascade algorithms/solutions for intersecting/breaking/healing/combining wires, edges, faces, shapes, shape analysis, shape upgrade, closed area detection, closer wire extraction the only solution that worked in all cases for making a Face intersection algorithm was extremely simple: fuse all shapes and explore the resulting faces. Also Face colliding detection was made by using BRepAlgoAPI_Common algorithm and see if Face exploring iterator holds anything. The problem with these solutions is that they are not the fastest, the advantage is that they work well and cover most usage cases.
Saturday, September 26, 2009
Trianglation with two triangles
Triangulation do not work still, but with help of bxtrx, it was found the most likely problem is because I've did not use (as he said in previous blog post) all steps to do that triangulation. Also the solution may need some extra packages, but without making an over design with the C++ bridge that I was tried yesterday to do without a success on that.
I've continued the rest of the code around triangulation, and when triangulation is in place, it can be exported in an external file and processed. So I've created a special action to do triangulation. The test right now works with a face of two shapes that defines a square. Fixing it's bugs will may have various applications, mostly to export transparently shapes to "outer world".
Hope with adding of those extra packages and minimal fixes to see before release (setup in the midle of the next week) an interesting usage of triangulation.
I've continued the rest of the code around triangulation, and when triangulation is in place, it can be exported in an external file and processed. So I've created a special action to do triangulation. The test right now works with a face of two shapes that defines a square. Fixing it's bugs will may have various applications, mostly to export transparently shapes to "outer world".
Hope with adding of those extra packages and minimal fixes to see before release (setup in the midle of the next week) an interesting usage of triangulation.
Solving problems at C# OpenCascade applications
While developing a .Net application using the OpenCascade wrappers, some issues might appear: like an unexpected crash or a function that returns nothing when it should return some list with processed elements and no clue why it is not working. There could be many causes of the problem, among them there are:
- incorrect usage of the class (forgot to initialize something),
- correct usage of the class but incorrect parameters or not treating the error that the operation returned and moving to next steps (like the operation failed silently and I am trying to access the result shape),
- bug in the wrappers (some parameter not passed correctly to the native layer) - not typical but not excluded,
- bug in OpenCascade - not typical but not excluded.
Because investigating all these problems might take a lot of time I will explain from my experience with wrappers until now how to approach the problem to solve it quickly.
Let's assume that I write some OpenCascade code in C# and it doesn't work. I try one or two constructors for the class, I try the same function with different parameters but still the class/algorithm returns no results and I have no clue what's the problem. The problem can be in the C# layer, in the wrappers or in OpenCascade. Assuming (because of the lack of samples) that I am not sure how to use the class properly or even if this is the algorithm class that solves my problem, also I am not sure if the problem is on my layer or lower layers, I do the following:
1. Because the code is already written the first thing I would do is to use the OpenCascade error handling mechanism to see if there is a problem.
To detail further this sentence: majority of the classes have the IsDone() method that should return true, also many algorithms classes have some function to get the operation status (they return something like OK, could not allocate memory, invalid parameters). Modeling algorithms docs have some hints on these.
If all these look ok we move to the step 2.
2. If the result that I expect is an array of shapes, or some values I look at the class for functions related to the algorithm that might give me a hint what happened. I look at result array length if it is 0, or if the class has some methods that describe the solution like NbPoints() or IsGeneratedNewShape(). If all these are 0/false a possibility would be that I didn't initialize the algorithm properly so it couldn't find a solution. I always look for Intialize() functions.
3. This step could be a step before step 1, before starting to implement the algorithm.
Replicate the functionality with Draw Test Harness. I make quickly a similar shape using tcl, apply the algorithm and see if this works. If it doesn't work it might be an OpenCascade bug, if it works I look at the command source code to see how they implemented the code.
A problem here might be that I can't always find a command close to the functionality that I want to implement. An advantage would be that looking at their code I get the confirmation that I use the right path for my solution.
4. Search on forum for the problem. If some sample code is found in C++ I can always try it with copy paste on one of the mfc sample applications provided together with OCC. Also I look if the class usage is like the one from my code.
5. If none of the above steps to detect the problem worked I try to implement myself the solution in C++ to eliminate the wrapper layer. If it works in C++ we have a wrapper problem, if it doesn't it's an incorrect class usage problem or an OpenCascade bug.
6. The last solution and most time consuming one is to debug the OpenCascade function. I look first at the source codes to try to get a hint on why my code fails (maybe I see a check there if a parameter is a Face type shape). In many cases I find there some code that I don't understand and gives no clue why it doesn't work. An approach for it is to debug it while doing some operation to see where it stops or crashes.
How to debug:
- first we have to build OpenCascade in debug mode. Using VisualStudio this can be made by going to OpenCASCADE6.3.0\ros\adm\win32\vc8\ and build the projects found there. Some projects might fail building because they depend on other projects so we try again after building the others. Some always fail, we can always copy from the release folder the release version of these especially if we are not interested debugging these missing libraries,
- make the CASROOT environment variable point to our debug folder or rename our debug folder with the name of the release folder, make sure we use the debug folder by renaming the release folder and see if sample applications work,
- launch the C#/.Net/C++ application, attach to it with a debugger and put a breakpoint in the OpenCascade function that we want to debug. In the trunk in NaroCad folder there is a file named DebuggingSolution.txt that explains in detail how to configure WinDbg to debug OpenCascade.
From debugging I made until now there is no point to have wrappers in debug mode, you can always check in the native OpenCascade code if the parameters passed are correct or garbled.
After all these debugging preparations if we don't understand the native code a chance would be to be lucky and have the code failing on some "if" check or see some message thrown that can give us a hint.
7. The final step would be always to start again from step 1 (or 3) searching for a completely different solution.
Many variations on the order of these steps can be done I just wanted to make a list of possibilities that can help us find a quick and reliable solution.
- incorrect usage of the class (forgot to initialize something),
- correct usage of the class but incorrect parameters or not treating the error that the operation returned and moving to next steps (like the operation failed silently and I am trying to access the result shape),
- bug in the wrappers (some parameter not passed correctly to the native layer) - not typical but not excluded,
- bug in OpenCascade - not typical but not excluded.
Because investigating all these problems might take a lot of time I will explain from my experience with wrappers until now how to approach the problem to solve it quickly.
Let's assume that I write some OpenCascade code in C# and it doesn't work. I try one or two constructors for the class, I try the same function with different parameters but still the class/algorithm returns no results and I have no clue what's the problem. The problem can be in the C# layer, in the wrappers or in OpenCascade. Assuming (because of the lack of samples) that I am not sure how to use the class properly or even if this is the algorithm class that solves my problem, also I am not sure if the problem is on my layer or lower layers, I do the following:
1. Because the code is already written the first thing I would do is to use the OpenCascade error handling mechanism to see if there is a problem.
To detail further this sentence: majority of the classes have the IsDone() method that should return true, also many algorithms classes have some function to get the operation status (they return something like OK, could not allocate memory, invalid parameters). Modeling algorithms docs have some hints on these.
If all these look ok we move to the step 2.
2. If the result that I expect is an array of shapes, or some values I look at the class for functions related to the algorithm that might give me a hint what happened. I look at result array length if it is 0, or if the class has some methods that describe the solution like NbPoints() or IsGeneratedNewShape(). If all these are 0/false a possibility would be that I didn't initialize the algorithm properly so it couldn't find a solution. I always look for Intialize() functions.
3. This step could be a step before step 1, before starting to implement the algorithm.
Replicate the functionality with Draw Test Harness. I make quickly a similar shape using tcl, apply the algorithm and see if this works. If it doesn't work it might be an OpenCascade bug, if it works I look at the command source code to see how they implemented the code.
A problem here might be that I can't always find a command close to the functionality that I want to implement. An advantage would be that looking at their code I get the confirmation that I use the right path for my solution.
4. Search on forum for the problem. If some sample code is found in C++ I can always try it with copy paste on one of the mfc sample applications provided together with OCC. Also I look if the class usage is like the one from my code.
5. If none of the above steps to detect the problem worked I try to implement myself the solution in C++ to eliminate the wrapper layer. If it works in C++ we have a wrapper problem, if it doesn't it's an incorrect class usage problem or an OpenCascade bug.
6. The last solution and most time consuming one is to debug the OpenCascade function. I look first at the source codes to try to get a hint on why my code fails (maybe I see a check there if a parameter is a Face type shape). In many cases I find there some code that I don't understand and gives no clue why it doesn't work. An approach for it is to debug it while doing some operation to see where it stops or crashes.
How to debug:
- first we have to build OpenCascade in debug mode. Using VisualStudio this can be made by going to OpenCASCADE6.3.0\ros\adm\win32\vc8\ and build the projects found there. Some projects might fail building because they depend on other projects so we try again after building the others. Some always fail, we can always copy from the release folder the release version of these especially if we are not interested debugging these missing libraries,
- make the CASROOT environment variable point to our debug folder or rename our debug folder with the name of the release folder, make sure we use the debug folder by renaming the release folder and see if sample applications work,
- launch the C#/.Net/C++ application, attach to it with a debugger and put a breakpoint in the OpenCascade function that we want to debug. In the trunk in NaroCad folder there is a file named DebuggingSolution.txt that explains in detail how to configure WinDbg to debug OpenCascade.
From debugging I made until now there is no point to have wrappers in debug mode, you can always check in the native OpenCascade code if the parameters passed are correct or garbled.
After all these debugging preparations if we don't understand the native code a chance would be to be lucky and have the code failing on some "if" check or see some message thrown that can give us a hint.
7. The final step would be always to start again from step 1 (or 3) searching for a completely different solution.
Many variations on the order of these steps can be done I just wanted to make a list of possibilities that can help us find a quick and reliable solution.
Friday, September 25, 2009
Crash on triangulation and C++ bridge work
A bad part of OpenCascade used from .Net is debugging. NaroCAD have wrappers but is practically impossible to make an easy way to make debugging without recompiling wrappers. Depending on your machine, it may take some time, and even on a powerful machine may take more than one minute only the linking.
As OpenCascade offers samples that make triangulation and seem to crash, I've looked for alternate implementations on OpenCascade forum. As it seem to crash, the debugging from C# level makes it hard to see what happen in beneath or if I've have an invalid pointer, etc.
So I do try to make a valid prototype that will work separately from wrappers, that Naro can use it to be called from outside. Right now I'm hit by various C++/CLI only errors like: "property XXX cannot be used in this context because the get accessor is inaccessible" but is defined as public in wrappers, so some wrapper patching may still be needed, but only once. It seem I'm close but yet I've not found the right way to make it work.
As OpenCascade offers samples that make triangulation and seem to crash, I've looked for alternate implementations on OpenCascade forum. As it seem to crash, the debugging from C# level makes it hard to see what happen in beneath or if I've have an invalid pointer, etc.
So I do try to make a valid prototype that will work separately from wrappers, that Naro can use it to be called from outside. Right now I'm hit by various C++/CLI only errors like: "property XXX cannot be used in this context because the get accessor is inaccessible" but is defined as public in wrappers, so some wrapper patching may still be needed, but only once. It seem I'm close but yet I've not found the right way to make it work.
Thursday, September 24, 2009
Bug fixing part IV or not really
Today I've debugged some issues at Undo/Redo breakup and load/save issues. Load/save issues are in fact from NaroCAD point of view like applying a redo operation.
There was two issues I've long stand to see if they are issues on Undo/Redo step. Those issues were mainly propagation that seem just to not apply and the lose of transformations at Undo/Redo operations.
Because of refactoring with face splitting it seem for now as a side effect there is a propagation problem, I've tried to deletate bxtrx to do it and he agrees.
The other issue I was not so lucky, in fact, I've did a refactor that affects mostly transformation code. So it may appear that transformations do not apply. Doing any test makes that transformations get values that are not identity matrix and appears to apply them in code, but at the end the shape was not transformed. So, I've asked Devasted (as he is the original author of them) to see if something I've did wrong. And it seem that I've don't and may be a regression of the same refactor with face splitting. I'm not sure yet but for now is best to wait till the face splitting part will be remade and see if for real the transformation code it really aplies or not.
I will try to look on bugs that are already in known bugs.
There was two issues I've long stand to see if they are issues on Undo/Redo step. Those issues were mainly propagation that seem just to not apply and the lose of transformations at Undo/Redo operations.
Because of refactoring with face splitting it seem for now as a side effect there is a propagation problem, I've tried to deletate bxtrx to do it and he agrees.
The other issue I was not so lucky, in fact, I've did a refactor that affects mostly transformation code. So it may appear that transformations do not apply. Doing any test makes that transformations get values that are not identity matrix and appears to apply them in code, but at the end the shape was not transformed. So, I've asked Devasted (as he is the original author of them) to see if something I've did wrong. And it seem that I've don't and may be a regression of the same refactor with face splitting. I'm not sure yet but for now is best to wait till the face splitting part will be remade and see if for real the transformation code it really aplies or not.
I will try to look on bugs that are already in known bugs.
Box drawing
Reimplemented the Box drawing tool to have the same style of working like Extrude. The last details of it will be finished today.
Will continue with improving the Cut functionality and the face intersection tool.
Will continue with improving the Cut functionality and the face intersection tool.
Bug fixing part III
As those days we look on found problems we had in the PRE version there is a lot of work as we found problems like.
I had found possible problem in wrappers (if you have path with unicode characters and the methods like save-file may file), I had cleaned up small problems in view actions like top/left/, view dialogs were fixed with the last found issues. Also both because of crashing stack reports that looks somehow broken, I've replaced in action to not do a SCSF call, but to do a direct call where was possible and do not break the design. In the same manner I've replaced that all actions to get an work item to reduce the copy/paste code.
Right now I look on a Undo/Redo work that makes transformation not to apply. They do apply but seems to have no effect.
Note: there is an implementation of triangulation I am working on (based on OCC one) and try to find a possible usage for it.
I had found possible problem in wrappers (if you have path with unicode characters and the methods like save-file may file), I had cleaned up small problems in view actions like top/left/, view dialogs were fixed with the last found issues. Also both because of crashing stack reports that looks somehow broken, I've replaced in action to not do a SCSF call, but to do a direct call where was possible and do not break the design. In the same manner I've replaced that all actions to get an work item to reduce the copy/paste code.
Right now I look on a Undo/Redo work that makes transformation not to apply. They do apply but seems to have no effect.
Note: there is an implementation of triangulation I am working on (based on OCC one) and try to find a possible usage for it.
Monday, September 21, 2009
Shape intersection
Finalized the first version of shape intersection algorithm so that when closed 2D shapes are drawn they are intersected with the other shapes drawn. This also works well with the AutoGroup algorithm that automatically creates closed wires from opened wires drawn (like arc, line, spline).
On the screenshots below you can see various shapes intersecting (including a rectangle generated with AutoGroup). Some of the small shapes resulted after intersection are extruded. There are still problems to be solved: it interferes with Cut that generates a single shape after applying, the small parts on which a feature like extrude is applied should be eliminated from the intersection algorithm list.


On the screenshots below you can see various shapes intersecting (including a rectangle generated with AutoGroup). Some of the small shapes resulted after intersection are extruded. There are still problems to be solved: it interferes with Cut that generates a single shape after applying, the small parts on which a feature like extrude is applied should be eliminated from the intersection algorithm list.


Saturday, September 19, 2009
NaroCAD 1.2PRE (Sneak peak)
NaroCAD had a long way to go, and it improves day by day.
Around two months and a half NaroCAD gets 1.0 meaning we had a stable framework, we can run OpenCascade on top of .NET, we did had some basic shapes and some tools.
Today the Naro team which contains contributions from bxtrx, me, Devasted and help on testing by Chris, Van-Sy and Achim mostly (and you the users by submiting the crash reports to Naro), it gets a lot of small improvements, but still it has it's own problems.
Right now we are glad to show to you what all those changes you've seen in blog are about.
In short what are changes from 1.0:
- transformations
- (simple) constraints
- streamlined UI for most operations (dynamic help, filtering in treeview for picking shapes, categories for shapes, improved looks, full-screen
- completely new shapes and operations (like face grouping, sweep (pipe), revolve, sphere, boolean operations, tagging for shape visibility)
- advanced Lua integration for simple shape creation
- option dialogs that gives posibility to disable solver, add metrics units and to show/hide toolbars basedon your usage
- copy-paste (by Control+C - Control+V)
- this is first version that uses NaroLinker meaning that the OpenCascade wrappers are slimmer (around 7M instead 20M) which makes the final installer to be 1M smaller and reduce the first start memory footprint by 10M
- a lot others!
Hope you will like this PRE release and based on your feedback, it can be done even better, fixes can be found.
So download it from NaroCAD Sourceforge page from here: https://sourceforge.net/projects/narocad/
Around two months and a half NaroCAD gets 1.0 meaning we had a stable framework, we can run OpenCascade on top of .NET, we did had some basic shapes and some tools.
Today the Naro team which contains contributions from bxtrx, me, Devasted and help on testing by Chris, Van-Sy and Achim mostly (and you the users by submiting the crash reports to Naro), it gets a lot of small improvements, but still it has it's own problems.
Right now we are glad to show to you what all those changes you've seen in blog are about.
In short what are changes from 1.0:
- transformations
- (simple) constraints
- streamlined UI for most operations (dynamic help, filtering in treeview for picking shapes, categories for shapes, improved looks, full-screen
- completely new shapes and operations (like face grouping, sweep (pipe), revolve, sphere, boolean operations, tagging for shape visibility)
- advanced Lua integration for simple shape creation
- option dialogs that gives posibility to disable solver, add metrics units and to show/hide toolbars basedon your usage
- copy-paste (by Control+C - Control+V)
- this is first version that uses NaroLinker meaning that the OpenCascade wrappers are slimmer (around 7M instead 20M) which makes the final installer to be 1M smaller and reduce the first start memory footprint by 10M
- a lot others!
Hope you will like this PRE release and based on your feedback, it can be done even better, fixes can be found.
So download it from NaroCAD Sourceforge page from here: https://sourceforge.net/projects/narocad/
Thursday, September 17, 2009
Bug fixing part II
Some bugs were fixed from the last session like: wrong undo/redo naming on rectangle, box modifier is changed to be defined with a dialog (is experimental for now, probably fixing the current SVN action may remove this dialog), disabling current action may not lead to set the action None and the help is not changed, visible selection for boolean operations and switching to None right after, gp_Pnt class is not visible from debugger, the code was changed in most places with a C# implementation (Point3D class), installer works again,
Wednesday, September 16, 2009
Splitting algorithm, new wrappers
Succeeded to implement (using the TestHarness tool) an algorithm that splits into smaller Faces a Face that contains a complex wire made from smaller closed wires.
Tested on various cases and it seems to work well.
In order to implement a FaceSplitter function and its dependencies that implement the code from the script we need to wrap the ShapeUpgrade and ShapeFix packages. With this occasion made a FileGeneratingHowToStepByStep.txt file that explains in high detail how the wrappers for these packages were generated.
Estimated to finish tomorrow compiling the new wrappers and the NaroCad face splitting functionality.
Tested on various cases and it seems to work well.
In order to implement a FaceSplitter function and its dependencies that implement the code from the script we need to wrap the ShapeUpgrade and ShapeFix packages. With this occasion made a FileGeneratingHowToStepByStep.txt file that explains in high detail how the wrappers for these packages were generated.
Estimated to finish tomorrow compiling the new wrappers and the NaroCad face splitting functionality.
Tuesday, September 15, 2009
Draw Test Harness quick tutorial
OpenCascade has a very useful tool named Draw Test Harness. This tutorial presents two use cases that show how this tool can be used to research if some algorithms are appropriate for some implementation or not.
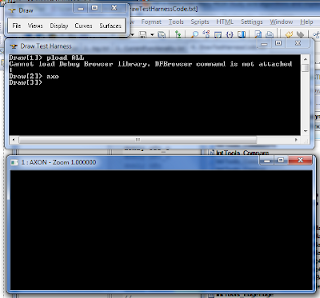
Preparing the tool:
- Launch Draw Test Harness (in can be launched by clicking on Start->Programs->OpenCascade Technology 6.3.0->Test Harness,
- on the command line write: pload ALL,
- then write: axo.
This loads all the occ packages and opens an axonometric view.
The result is displayed on the screenshot:
Use case 1: let's assume we want to find a way to combine two concentric circles so that the smaller one removes material from the bigger one. With test harness we can try different operations on the circles as wires or as faces to see which one fits our purpose. We can test with forward and reversed shapes, wires and faces and any other situation that we need to test.
The code is the following:
 circle c1 0 0 0 50
circle c1 0 0 0 50
circle c2 0 0 0 25
fit
mkedge ec1 c1 0 2*pi
mkedge ec2 c2 0 2*pi
wire wc1 ec1
wire wc2 ec2
mkplane p1 wc1
mkplane p2 wc2
bcut result p1 p2
donly result
And the result:
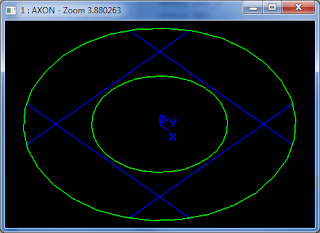
Another advantage beside the quick case testing would be also that we can look at the command source code to see how they are implemented.
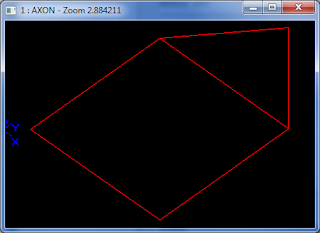
Use case2: we want to want to make some tests with FreeBounds from the ShapeAnalysis package to see if we can use this class to detect some closed wires. We write quickly some code to analyze the result:
 clear
clear
vertex v1 10 10 0
vertex v2 10 100 0
vertex v3 100 100 0
vertex v4 100 10 0
vertex v5 50 150 0
edge e1 v1 v2
edge e2 v2 v3
edge e3 v3 v4
edge e4 v4 v1
edge e5 v2 v5
edge e6 v5 v3
wire w1 e1 e2 e3 e4 e5 e6
mkplane p1 w1
freebounds p1 0
donly p1_o
We can modify the code to test what happens if we build two wires from these edges or any other case that we are interested in. Another cool thing is that we can always peek at the command implementation.
And the result:
Preparing the tool:
- Launch Draw Test Harness (in can be launched by clicking on Start->Programs->OpenCascade Technology 6.3.0->Test Harness,
- on the command line write: pload ALL,
- then write: axo.
This loads all the occ packages and opens an axonometric view.
The result is displayed on the screenshot:

Use case 1: let's assume we want to find a way to combine two concentric circles so that the smaller one removes material from the bigger one. With test harness we can try different operations on the circles as wires or as faces to see which one fits our purpose. We can test with forward and reversed shapes, wires and faces and any other situation that we need to test.
The code is the following:
circle c1 0 0 0 50circle c2 0 0 0 25
fit
mkedge ec1 c1 0 2*pi
mkedge ec2 c2 0 2*pi
wire wc1 ec1
wire wc2 ec2
mkplane p1 wc1
mkplane p2 wc2
bcut result p1 p2
donly result
And the result:

Another advantage beside the quick case testing would be also that we can look at the command source code to see how they are implemented.
Use case2: we want to want to make some tests with FreeBounds from the ShapeAnalysis package to see if we can use this class to detect some closed wires. We write quickly some code to analyze the result:
clearvertex v1 10 10 0
vertex v2 10 100 0
vertex v3 100 100 0
vertex v4 100 10 0
vertex v5 50 150 0
edge e1 v1 v2
edge e2 v2 v3
edge e3 v3 v4
edge e4 v4 v1
edge e5 v2 v5
edge e6 v5 v3
wire w1 e1 e2 e3 e4 e5 e6
mkplane p1 w1
freebounds p1 0
donly p1_o
We can modify the code to test what happens if we build two wires from these edges or any other case that we are interested in. Another cool thing is that we can always peek at the command implementation.
And the result:

Thursday, September 10, 2009
Opinion: It's C# faster than C++?
I will write my point starting from another blog post of one Java enterprise solution provider. In short it states this: for medium/large programs Java is fast(er) than C/C++.
Before stating any comparison between any platforms, we must understand how works VM programs compared with compiled programs. C# and Java are programs that targets a VM (Virtual Machine) and C++ creates an executable. The main difference between those two is that the VM instructions are not the processor instructions, but are some abstract, independent codes. Those are smaller and easier to compile but they are not processor instructions.
In contrast how it is a C++ application made: a developer writes his code in C++ (or C), there is a compiler that understand what he/she writes, it creates an application that calls from operating system various functionality and for code that developer writes the CPU instructions. The compile time may take some time, like a full blown application like OpenOffice may take more than 10 hours on a 2GHz+ CPU.
How a Java/C# application is made: a compiler does simply translates in simple statements that are much higher level than instructions and makes a bytecode application. It is named .class or .jar in Java (Jar is a zip archive that contains more .class files) or .exe or .dll that contains MSIL code. At running time, a runtime, named JIT, for only functions that are called by your program will make the corresponding machine instructions. Also, a difference is that most JITs come with automatical memory management compared when C++ does not. There are still C++ garbage collectors still. The garbage collector have the big advantages of cache locality and really cheap allocation of small objects, but have the disadvantage of pauses when the automatically memory cleanup occurs.
Judging technologically, a JIT, should get better performance than a static compiler like C++. Some of the reasons are: it knows the target machine, so it can align data and rearange structs in memory, it can use paralel instructions that the host machine supports, just because only the used code is translated in instructions, for large frameworks will mean that it will get better cache locality, it can inline for specific cases functions that are in other libraries as they are bytecode instructions, not effective code. Also, the garbage collector should bring an almost cost-free allocation and better cache locality. The dynamic nature of JIT it gives for it equal or more informations than any static compiler may get.
In practice anyway, I must disagree that a Java/.NET virtual machine can bring the same performance on the same code than a C++. For a specific loop you may get similar performance but using the CPU tunning on new compilers, profile guided optiomizations (which gets dynamic information of how your application behaves and gets almost the same information that a JIT have), the ability to do custom made memory allocator (a common used one for embeded programming is named: circular buffer, which to allocate an item is as cheap as a garbage collector alloc, meaning an pointer add, but without the disadvantage of pauses that garbage collector gives), the bridge from outside world, meaning that the calls to a native operating system, are always made through a translating layer (named JNI or PInvoke) that imply some overhead as marshaling, C++ can be linked with other object files that can be optimized in assembly by CPU makers. Also, the long compiling time it also translates in a lot of more analisys that is done by static compilers to get the latest drop of performance.
The good side is that .NET or Java gives in their field just enough performance. Also, a well written algorithm can get much better performance regardless a language. Just by using Generics, you will get a big performance increase as there is no need for type checking (which means an overhead). Also, generic collections and LinQ will offer to you a good performance. The garbage collector does not guarantee to not have memory leaks, but guarantees to you to not have double deleted pointers or invalid pointers at all. When you access a pointer is either null or a data of the type you've specified. Where C#/.NET or Java are strong are mostly: integer operations, inlining function calls and constant propagation over a satelite/external assembies, the string operations, fast heap allocations, after startup they run enough fast that you will not notice that is an bytecode application.
The last thing that is important regarding speed: sometimes the speed is measured wrong. NaroCAD shows in profiling that it's abstraction layer is enough easy to work and the slowest thing is for now not the JIT or the runtime, but the C++/OpenCascade code. Not because OpenCascade is slow, but because OpenCascade as C++ code did not achieved yet as it has a complex codebase too much time to be optimized.
There is only one point I want it to make regarding speed. On a cheap laptop of those days you can make a clean build of NaroCAD that have more than 800 classes in 17 seconds and to build after a change in 3 seconds, that mostly imples to copy assemblies to a destination folder. At startup it loads all OpenCascade libraries, Windows dlls like UI ones make JIT for anything it needs like the component framework will take 10 seconds. From it, JIT is somelike 5-6 seconds to compile almost all NaroCAD, so as long as you will use more functionality, you will have over time around 2-3 seconds of extra jitt-ing, means a 0.1 delay on every operation only for the first time. If you don't want to wait for those 5 seconds and to improve dramatically the startup speed of NaroCAD, you can add a command like that using NGen: run cmd as administrator and from the folder of NaroCAD write: C:\Windows\Microsoft.NET\Framework\v2.0.50727\ngen.exe install narocad.exe
Before stating any comparison between any platforms, we must understand how works VM programs compared with compiled programs. C# and Java are programs that targets a VM (Virtual Machine) and C++ creates an executable. The main difference between those two is that the VM instructions are not the processor instructions, but are some abstract, independent codes. Those are smaller and easier to compile but they are not processor instructions.
In contrast how it is a C++ application made: a developer writes his code in C++ (or C), there is a compiler that understand what he/she writes, it creates an application that calls from operating system various functionality and for code that developer writes the CPU instructions. The compile time may take some time, like a full blown application like OpenOffice may take more than 10 hours on a 2GHz+ CPU.
How a Java/C# application is made: a compiler does simply translates in simple statements that are much higher level than instructions and makes a bytecode application. It is named .class or .jar in Java (Jar is a zip archive that contains more .class files) or .exe or .dll that contains MSIL code. At running time, a runtime, named JIT, for only functions that are called by your program will make the corresponding machine instructions. Also, a difference is that most JITs come with automatical memory management compared when C++ does not. There are still C++ garbage collectors still. The garbage collector have the big advantages of cache locality and really cheap allocation of small objects, but have the disadvantage of pauses when the automatically memory cleanup occurs.
Judging technologically, a JIT, should get better performance than a static compiler like C++. Some of the reasons are: it knows the target machine, so it can align data and rearange structs in memory, it can use paralel instructions that the host machine supports, just because only the used code is translated in instructions, for large frameworks will mean that it will get better cache locality, it can inline for specific cases functions that are in other libraries as they are bytecode instructions, not effective code. Also, the garbage collector should bring an almost cost-free allocation and better cache locality. The dynamic nature of JIT it gives for it equal or more informations than any static compiler may get.
In practice anyway, I must disagree that a Java/.NET virtual machine can bring the same performance on the same code than a C++. For a specific loop you may get similar performance but using the CPU tunning on new compilers, profile guided optiomizations (which gets dynamic information of how your application behaves and gets almost the same information that a JIT have), the ability to do custom made memory allocator (a common used one for embeded programming is named: circular buffer, which to allocate an item is as cheap as a garbage collector alloc, meaning an pointer add, but without the disadvantage of pauses that garbage collector gives), the bridge from outside world, meaning that the calls to a native operating system, are always made through a translating layer (named JNI or PInvoke) that imply some overhead as marshaling, C++ can be linked with other object files that can be optimized in assembly by CPU makers. Also, the long compiling time it also translates in a lot of more analisys that is done by static compilers to get the latest drop of performance.
The good side is that .NET or Java gives in their field just enough performance. Also, a well written algorithm can get much better performance regardless a language. Just by using Generics, you will get a big performance increase as there is no need for type checking (which means an overhead). Also, generic collections and LinQ will offer to you a good performance. The garbage collector does not guarantee to not have memory leaks, but guarantees to you to not have double deleted pointers or invalid pointers at all. When you access a pointer is either null or a data of the type you've specified. Where C#/.NET or Java are strong are mostly: integer operations, inlining function calls and constant propagation over a satelite/external assembies, the string operations, fast heap allocations, after startup they run enough fast that you will not notice that is an bytecode application.
The last thing that is important regarding speed: sometimes the speed is measured wrong. NaroCAD shows in profiling that it's abstraction layer is enough easy to work and the slowest thing is for now not the JIT or the runtime, but the C++/OpenCascade code. Not because OpenCascade is slow, but because OpenCascade as C++ code did not achieved yet as it has a complex codebase too much time to be optimized.
There is only one point I want it to make regarding speed. On a cheap laptop of those days you can make a clean build of NaroCAD that have more than 800 classes in 17 seconds and to build after a change in 3 seconds, that mostly imples to copy assemblies to a destination folder. At startup it loads all OpenCascade libraries, Windows dlls like UI ones make JIT for anything it needs like the component framework will take 10 seconds. From it, JIT is somelike 5-6 seconds to compile almost all NaroCAD, so as long as you will use more functionality, you will have over time around 2-3 seconds of extra jitt-ing, means a 0.1 delay on every operation only for the first time. If you don't want to wait for those 5 seconds and to improve dramatically the startup speed of NaroCAD, you can add a command like that using NGen: run cmd as administrator and from the folder of NaroCAD write: C:\Windows\Microsoft.NET\Framework\v2.0.50727\ngen.exe install narocad.exe
Tuesday, September 8, 2009
Bug fixes (part 1 of ... )
Naro did have fairly big amount of features from 1.0 release.
Right now we work hard to create the version 1.2 based mostly on 1.0 codebase. There are issues here and there and right now my principal focus is to target them.
The single "feature" implemented in the last day was that Lua arguments' dialog will have to be created with a default value. Also, Lua script with gear did not work well because was a bug of auto-generating faces. The bug was because the underlined lines were transformed.
So for now only bug fixes will be my major focus. If you want to compile Naro from SVN you can report bugs and crashes here as comments, or to email or to sourceforge bug tracker we will work hard to track down those issues.
Right now we work hard to create the version 1.2 based mostly on 1.0 codebase. There are issues here and there and right now my principal focus is to target them.
The single "feature" implemented in the last day was that Lua arguments' dialog will have to be created with a default value. Also, Lua script with gear did not work well because was a bug of auto-generating faces. The bug was because the underlined lines were transformed.
So for now only bug fixes will be my major focus. If you want to compile Naro from SVN you can report bugs and crashes here as comments, or to email or to sourceforge bug tracker we will work hard to track down those issues.
Sunday, September 6, 2009
Metric units defined
 Metric units are saved in document data. There is a section specific in Tools options that you can setup the metrics options and to not be buggied again with it. For now this option is stored only as a scale factor but is not yet used anywhere. It may be useful for persons that wants to know the metrics or it may be useful when importing other shapes (not yet working) to use this scaling factor directly.
Metric units are saved in document data. There is a section specific in Tools options that you can setup the metrics options and to not be buggied again with it. For now this option is stored only as a scale factor but is not yet used anywhere. It may be useful for persons that wants to know the metrics or it may be useful when importing other shapes (not yet working) to use this scaling factor directly.
Lua visual arguments
 Lua scripting supports to define arguments to scripts that can be created dynaimically.
Lua scripting supports to define arguments to scripts that can be created dynaimically.It is easy to setup the arguments in your script as follows:
beginArgumentSection(Name)
For every argument you will have to write it's type and name that describes it like:
addArgument[Boolean | Integer | Real | String | Shape](NameArgument)
If you don't want default values for them, you will be able to setup them like this:
setArgument[Boolean | Integer | Real | String | Shape](NameArgument, newValue)
At the end you will need to execute function: showArguments()
To use in your script simply assign your variables with getter functions as follows:
luaVariable = getArgument[Boolean | Integer | Real | String | Shape](NameArgument)
For the predefined gear in the previous blog post, there were 5 parameters, 4 reals and one integer. To setup them the code for it is as follows:
beginArgumentSection("Gear")
addArgumentReal("Inner Range", "Inner angle")
setArgumentReal("Inner Range", 320)
addArgumentReal("Outer Range", "Outer Range")
setArgumentReal("Outer Range", 400)
addArgumentReal("Inner Angle Ratio", "Inner Angle Ratio")
setArgumentReal("Inner Angle Ratio", 0.4)
addArgumentReal("Outer Angle Ratio", "Outer Angle Ratio")
setArgumentReal("Outer Angle Ratio", 0.2)
addArgumentInteger("Steps", "Gear Steps")
setArgumentInteger("Steps", 20)
showArguments()
inner_range = getArgumentReal("Inner Range")
outer_range = getArgumentReal("Outer Range")
inner_angle_ratio = getArgumentReal("Inner Angle Ratio")
outer_angle_ratio = getArgumentReal("Outer Angle Ratio")
steps = getArgumentInteger("Steps")
In this way hopefully more complex scripts can be created as they will give feedback to user to create as complex scripts as they wish.
Those days I've also look for simple crashes that are in the actual code base and will give to you less chances to crash Naro from SVN version. Also, there is a Lua shape() function that will offer a way to you to pick your shape visually. There is a help() lua function that will bring to you a help window. The bad thing is that the Lua functions are not yet documented but they will be really soon.
Saturday, September 5, 2009
Fixed a lot of issues with document live cycle
Do you remember that document live cycle span was fixed previously? NaroCAD have a MVC architecture and the previous changes did guarantee that the document/model cannot get corrupted, but in fact happens that almost any other parts (the view and the controller) they get corrupted.
The most typical case was this: you start drawing a shape/feature and you edit in properties dialog something. It was invisible for you but it happens at that stage an inconsistent transact/commit as the current property change tries to change the document state. Making those changes will make subsequent changes of the shape that was not completely draw to fail. Sometimes makes to fail the entire Naro, or to appear weirednesses like double shapes in document tree, etc.
Right now when you change a property, you will be setup to the action None, meaning the edit mode.
The most typical case was this: you start drawing a shape/feature and you edit in properties dialog something. It was invisible for you but it happens at that stage an inconsistent transact/commit as the current property change tries to change the document state. Making those changes will make subsequent changes of the shape that was not completely draw to fail. Sometimes makes to fail the entire Naro, or to appear weirednesses like double shapes in document tree, etc.
Right now when you change a property, you will be setup to the action None, meaning the edit mode.
Thursday, September 3, 2009
Integer comparisons faster than string comparison in .NET
NaroCAD is as a high level diagram a high level CAD/CAM like framework on top of OpenCascade. Naro can stand independently of OpenCascade, it can have by design parametric modeling, a tree XML like document. Also all changes of what you see in NaroCAD are stored in a persistent way with undo/redo events.
This abstraction gives a lot of advantages mostly when you debug and when you work with your classes as you can stop your program, save all your custom attributes to NaroCAD tree (and can be stored in a file). They are also exposed as generic classes, meaning that you will mostly get a really clean as design class like.
As we've got Lua added to Naro we did found much easier the limitations of Naro. One of them is that may be slow (we did previous tests on Naro to fix the Undo/Redo times) mostly because the attribute like convention is string based, also the Undo/Redo have a big ram increase as it store everything.
Once we had a benchmark test and we found that a lot of time is spent in OpenCascade and Undo time. But as there are lies, lies and benchmarks, I've tried to optimize the performance on NaroCAD regardless of other components. As there is a specific blog just presenting OpenCascade performance, and NaroCAD is a framework on top of OpenCascade, we tried to optimize performance on NaroCAD framework level.
For this we used a Lua script to test how it behave Naro on performance level:
i = 0
while(i < 40000) do
line(0, 0, 0, 100, 100, 100)
i = i + 1
end
First, some persons may ask: why you draw 40000 lines? Why not 40000 circles? The answer was the problem we wanted to check: is Naro framework enough fast for most users? Is .NET platform not only easy to use, but fast for common operations? Also, we did wanted to make other components to be our code limitation, like OpenCascade or Windows.Forms TreeView's update speed, not the NaroCAD framework. By optimizing NaroCAD's framework the visualization of shapes using OpenCascade will be as limited as OpenCascade is.
What was found after doing this testing?
- Lua interpreter is really fast, I can say that you will feel it as real-time for even complex code
- OpenCascade it feels slow. It is CPU bound and the entire logic regarding OpenCascade we had, took a lot of CPU time (close to 30+ % before optimization to close to 40% of entire operation time after we've optimized). This time was mainly (90% of OCC time) one function: context.Display(AIS_Shape, false);
- NaroCAD wrapper have no penality regarding speed, but for small objects (like in our case, was a lot of small points), the Naro wrapper store a bridge pointer which may add a bit to memory consumption. So the solution is to store as much as possible from separate words in their worlds. I encourage you to write as much as possible in .NET language of your choice as is easier to debug and finish this code.
- Log.net's Debug function for this drawing task it took a hefty 5% of time. May not sound much, but a lot other operations took much less. This is because of disk IO I think and String.Concat calls that are made inside
- NaroCAD attribute lookup was fast, because was mostly binary search to locate a node and binary search to locate an attribute, but pays back on large(r) attribute/shape count. This is because we use SortedDictionary class (equivalent with C++ std::map). I've used strength reduction for calls, and right now attributes are located via integer operations instead string one. This in itself speeds up the Naro code by 25%. This is also combined with simplified attribute declaration and a mapped name for attribute. This will mean also that at first time you create an attribute and you add to Naro's document tree, you will be able to save this document.
- Undo/Redo used a lot of memory. And was slow. It was somelike for every shape you have declared in the Naro's document tree, you should have around 1.5 times more memory used for storing the Undo/Redo information. Right now we compute minimalist data needed like: we compute Undo but not Redo until is not needed. Also, the complex attributes like: Transform, Point3D, Layers are saved using helper methods that save/restore much faster arrays of integers and doubles. Those optimizations did make computing a 40k shapes tree to speedup with 75%. Also will mean a small memory decrease, depends a lot of your usage and the garbage collecting policy. For sure you will see some memory free. For debug purposes, I've make diffs to show their changes as an XML, but there is no visual way to see in NaroCAD. But may be interesting for users to see what changes they've did or what means an Undo for them.
- I've tried extreme solutions for Undo/Redo like zip-ing in-memory the diff datas, but I'm not sure if my algorithm have a bug, was a SharpZipLib bug or a .NET memory policy/bug, but the RAM usage was increased and the "gained" memory was added with the compressing/decompressing diff times. I've tried a forced GC.Collect to make things better but no changes.
Those code techniques will improve long usage/high count primitives usage cases that may appear in using NaroCAD. Also may make persons that considered OCAF tree was fast(er) than any "managed" or "interpreted" implementation to reconsider and to give to NaroCAD framework a try. It may be surprised in a good way about it's versatility and performance.
This abstraction gives a lot of advantages mostly when you debug and when you work with your classes as you can stop your program, save all your custom attributes to NaroCAD tree (and can be stored in a file). They are also exposed as generic classes, meaning that you will mostly get a really clean as design class like.
As we've got Lua added to Naro we did found much easier the limitations of Naro. One of them is that may be slow (we did previous tests on Naro to fix the Undo/Redo times) mostly because the attribute like convention is string based, also the Undo/Redo have a big ram increase as it store everything.
Once we had a benchmark test and we found that a lot of time is spent in OpenCascade and Undo time. But as there are lies, lies and benchmarks, I've tried to optimize the performance on NaroCAD regardless of other components. As there is a specific blog just presenting OpenCascade performance, and NaroCAD is a framework on top of OpenCascade, we tried to optimize performance on NaroCAD framework level.
For this we used a Lua script to test how it behave Naro on performance level:
i = 0
while(i < 40000) do
line(0, 0, 0, 100, 100, 100)
i = i + 1
end
First, some persons may ask: why you draw 40000 lines? Why not 40000 circles? The answer was the problem we wanted to check: is Naro framework enough fast for most users? Is .NET platform not only easy to use, but fast for common operations? Also, we did wanted to make other components to be our code limitation, like OpenCascade or Windows.Forms TreeView's update speed, not the NaroCAD framework. By optimizing NaroCAD's framework the visualization of shapes using OpenCascade will be as limited as OpenCascade is.
What was found after doing this testing?
- Lua interpreter is really fast, I can say that you will feel it as real-time for even complex code
- OpenCascade it feels slow. It is CPU bound and the entire logic regarding OpenCascade we had, took a lot of CPU time (close to 30+ % before optimization to close to 40% of entire operation time after we've optimized). This time was mainly (90% of OCC time) one function: context.Display(AIS_Shape, false);
- NaroCAD wrapper have no penality regarding speed, but for small objects (like in our case, was a lot of small points), the Naro wrapper store a bridge pointer which may add a bit to memory consumption. So the solution is to store as much as possible from separate words in their worlds. I encourage you to write as much as possible in .NET language of your choice as is easier to debug and finish this code.
- Log.net's Debug function for this drawing task it took a hefty 5% of time. May not sound much, but a lot other operations took much less. This is because of disk IO I think and String.Concat calls that are made inside
- NaroCAD attribute lookup was fast, because was mostly binary search to locate a node and binary search to locate an attribute, but pays back on large(r) attribute/shape count. This is because we use SortedDictionary class (equivalent with C++ std::map). I've used strength reduction for calls, and right now attributes are located via integer operations instead string one. This in itself speeds up the Naro code by 25%. This is also combined with simplified attribute declaration and a mapped name for attribute. This will mean also that at first time you create an attribute and you add to Naro's document tree, you will be able to save this document.
- Undo/Redo used a lot of memory. And was slow. It was somelike for every shape you have declared in the Naro's document tree, you should have around 1.5 times more memory used for storing the Undo/Redo information. Right now we compute minimalist data needed like: we compute Undo but not Redo until is not needed. Also, the complex attributes like: Transform, Point3D, Layers are saved using helper methods that save/restore much faster arrays of integers and doubles. Those optimizations did make computing a 40k shapes tree to speedup with 75%. Also will mean a small memory decrease, depends a lot of your usage and the garbage collecting policy. For sure you will see some memory free. For debug purposes, I've make diffs to show their changes as an XML, but there is no visual way to see in NaroCAD. But may be interesting for users to see what changes they've did or what means an Undo for them.
- I've tried extreme solutions for Undo/Redo like zip-ing in-memory the diff datas, but I'm not sure if my algorithm have a bug, was a SharpZipLib bug or a .NET memory policy/bug, but the RAM usage was increased and the "gained" memory was added with the compressing/decompressing diff times. I've tried a forced GC.Collect to make things better but no changes.
Those code techniques will improve long usage/high count primitives usage cases that may appear in using NaroCAD. Also may make persons that considered OCAF tree was fast(er) than any "managed" or "interpreted" implementation to reconsider and to give to NaroCAD framework a try. It may be surprised in a good way about it's versatility and performance.
Wednesday, September 2, 2009
Sketching improvement
In the last days worked at improving the sketching capabilities of NaroCad and the basic drawing concepts.
Mainly the Face will be the basic unit of drawing. An example on how this will affect the application: the rectangle tool will generate a wire that will be attached to a MakeFace function. In the tree view a Face node will appear having as child node a rectangle (all changes to the wire propagate and the Face is regenerated). On the Face can be applied a tool like Extrude. All the basic shapes will be built on this concept. The 2D tools will be adapted to work with these structures: the Fillet 2D will know how to modify the wire that generated the Face, will add a tool to add and remove wires from an existing Face. These will work together with the automatic face detector that searches for closed wires and generates Faces from them. Also grouping and ungrouping them will be easy.
This working style started to look like the Sketch concept found at the majority of modeling applications: every 2D drawing is found in the 3D space as a Sketch on which the Features can be applied.
Mainly the Face will be the basic unit of drawing. An example on how this will affect the application: the rectangle tool will generate a wire that will be attached to a MakeFace function. In the tree view a Face node will appear having as child node a rectangle (all changes to the wire propagate and the Face is regenerated). On the Face can be applied a tool like Extrude. All the basic shapes will be built on this concept. The 2D tools will be adapted to work with these structures: the Fillet 2D will know how to modify the wire that generated the Face, will add a tool to add and remove wires from an existing Face. These will work together with the automatic face detector that searches for closed wires and generates Faces from them. Also grouping and ungrouping them will be easy.
This working style started to look like the Sketch concept found at the majority of modeling applications: every 2D drawing is found in the 3D space as a Sketch on which the Features can be applied.
Tuesday, September 1, 2009
Lazily loading and generics
This is an advanced topic and is not necessarily related with NaroCAD (but I found this problem right now in NaroCAD codebase as I've did a refactor).
Just in case you are too much used with C++, or you've just setup your mindset to C++ way, I want to present a case I've met today and is pretty bad to find the problem in case you are not prepared with it.
In C++ the compiler/linker combination takes all global and static variables that are in a class and initialize them. This is great in singletons, so you can initialize singletons, or register a component (as does MFC in their macros to register windows and message mapped functions).
So let's consider the MFC case: you want to create a dialog via it's resource ID, which is an integer, and you know that is defined as a #define MAIN_DIALOG_ID 12314.
When you will do a CWnd *wnd = CreateWindowById(MAIN_DIALOG_ID); this code will mostly work just because in other C++, there is registered this MAIN_DIALOG_ID with a resource data enough to supply the dialog information.
In .NET, or in C# in particular, you can create classes that you want to register with their IDs and you will see that they are not registered.
Let's think to a DialogFactory that can register any ID based from your class that is derived from a particulary NaroWindowBase. Let's suppose that you create a class named ThisDiaog derived from NaroWindowBase. And to register it, you do somelike this: static bool toRegister = DialogFactory.Instance.Register(MAIN_DIALOG_ID);
Because toRegister is static, you would expect that by it's initializing to register your dialog, but this will not happen till you use in other class your ThisDialog. To register it, you should create an empty static method and to call it, or to do registering explicit. Or to use the type as Generic name out of context, but to use the type, and the registering will happen.
The good part is anyway this: in most cases you don't want to initialize static singletons that you don't ever use in your applications.
Just in case you are too much used with C++, or you've just setup your mindset to C++ way, I want to present a case I've met today and is pretty bad to find the problem in case you are not prepared with it.
In C++ the compiler/linker combination takes all global and static variables that are in a class and initialize them. This is great in singletons, so you can initialize singletons, or register a component (as does MFC in their macros to register windows and message mapped functions).
So let's consider the MFC case: you want to create a dialog via it's resource ID, which is an integer, and you know that is defined as a #define MAIN_DIALOG_ID 12314.
When you will do a CWnd *wnd = CreateWindowById(MAIN_DIALOG_ID); this code will mostly work just because in other C++, there is registered this MAIN_DIALOG_ID with a resource data enough to supply the dialog information.
In .NET, or in C# in particular, you can create classes that you want to register with their IDs and you will see that they are not registered.
Let's think to a DialogFactory that can register any ID based from your class that is derived from a particulary NaroWindowBase. Let's suppose that you create a class named ThisDiaog derived from NaroWindowBase. And to register it, you do somelike this: static bool toRegister = DialogFactory.Instance.Register
Because toRegister is static, you would expect that by it's initializing to register your dialog, but this will not happen till you use in other class your ThisDialog. To register it, you should create an empty static method and to call it, or to do registering explicit. Or to use the type as Generic name out of context, but to use the type, and the registering will happen.
The good part is anyway this: in most cases you don't want to initialize static singletons that you don't ever use in your applications.
Revolve added

After 2 weeks revolve was finally added to Naro (so long mainly to my endless lazyness and bicycle). It's implemented using OCBRepPrimAPI_MakeRevol routine. Nothing really special about building revolve shape: just pick shape to revolve first, than pick line (axis) to revolve around.
Seems now Naro have all core modelling capabilities that any serious editor must have, still looking forward to add more!
Glass Button (and others)... thank you
I want to thank for the very nice looking buttons created using Glass Button project. This creates a much more polish on our UI and in most of dialogs. This is itself is not such a big gain, but is a nice catchup and shows the power of opensource and innovation. Naro uses other opensource projects and thanks for every part of them, like: OpenCascade, SharpDevelop (for text editor and zip code for bug reports), Inno Setup, Lua, IronPython, etc.
So big thanks to those projects which makes NaroCAD possible (OpenCascade), installable (Inno Setup) and good looking (Glass Button).
So big thanks to those projects which makes NaroCAD possible (OpenCascade), installable (Inno Setup) and good looking (Glass Button).
Subscribe to:
Comments (Atom)
